
Optimizing Our API Retrieval Design
Medical record retrieval in minutes, not months.
“Why does it take days, weeks, or months to retrieve my own medical records or to transfer them between providers?”
“Why does the burden of moving records from one provider to another fall on me, the patient?”
Datavant isn’t trying to answer those thorny questions.
Our goal is to eliminate the need to ask them in the first place.
Broadly speaking, the Datavant Switchboard enables data requesters to connect to two types of data: de-identified data and identified data. Connecting identified data through the Switchboard solves the underlying problems for patients retrieving their medical records – problems most people have encountered interacting with the many nodes of healthcare in the US. But the problem of record retrieval doesn’t just exist for patients. It’s a problem for any entity attempting to locate medical records for a specific individual (i.e. other healthcare providers, insurance companies, law firms, etc.).
By way of our merger with Ciox, Datavant has moved into the center of the ecosystem of medical record retrieval. In 2022, we retrieved more than 60 million charts for health systems and insurers across the country. Most of this work was fulfilled through a time-consuming series of manual steps.
In order to retrieve electronic medical records (EMRs), Datavant connects to individual record provider APIs, but health data is fragmented and one API connection into an EMR provider will not provide access to all available patient data. A big step in this process was bringing our FHIR Worker online, but even with FHIR Worker, integrations remain difficult and bespoke, each requiring its own implementation.
Electronic medical record retrieval at scale
Building a system that can facilitate rapid medical record retrieval at scale demands that our Switchboard design be absolutely bottleneck-free. With that in mind, we came to the conclusion that our legacy API retrieval system was too slow, especially when dealing with millions of patient search requests. We decided to redesign our API retrieval system so that it could turn around requests in less than a day with minimal manual intervention, regardless of the size of the request.
To scale up to thousands of providers and 10 times our current chart volume with ease, we outlined three specific goals for the redesign:
- Design the retrieval system for person-based flow. (More on this below.)
- Design the retrieval system in such a way that if there is a bottleneck in the system, it is because of the provider API and not because of any characteristics of our system. In other words, we should be able to retrieve data as fast as the provider APIs can send it to us.
- Reduce system complexity by simplifying interfaces and interactions involved in API retrieval.
Person based flow: finding needles in invisible haystacks
In order to retrieve individuals’ records, we must connect directly to EMR vendors, such as Epic, that manage the electronic records for healthcare providers. The entity making the record request (a person, an insurance company, etc.) needs to provide the demographic information for the healthcare provider from which they are requesting records. That is, in a traditional manual record request, the requester needs to know where the record is located so that a human being can either call that location, or walk into that location to retrieve the record. Without that information, the request cannot be fulfilled because the proverbial haystack of records is, so to speak, invisible.
For seamless, on-demand record requests, we should be able to locate any record for any patient anywhere in the US, even if we don’t know where it is located. This is person-based flow, and it’s something that our Convenet product has already achieved in England because of England’s centralized health system and Convenet’s integration with the NHS-Spine.
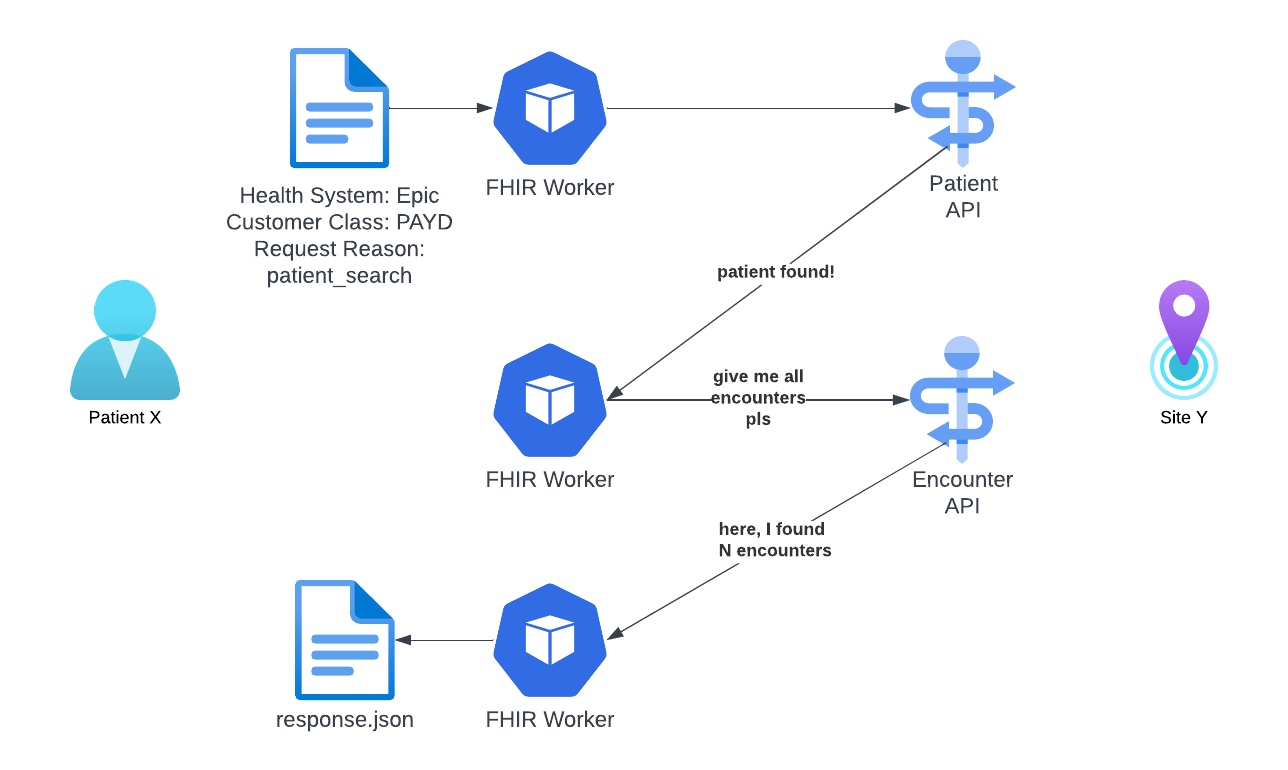
Our first steps toward realizing a person-based flow system was to set up geolocation matching to find potential healthcare providers and use our embedded API connections for patient search and chart retrievals. Using Lightweight instructions to check the patient’s existence and encounters within the given site, and repeat for all sites within Datavant’s network under the given patient’s geological proximity (based on zip code), we can locate records for individuals without prior knowledge of their location.
Eliminating system bottlenecks
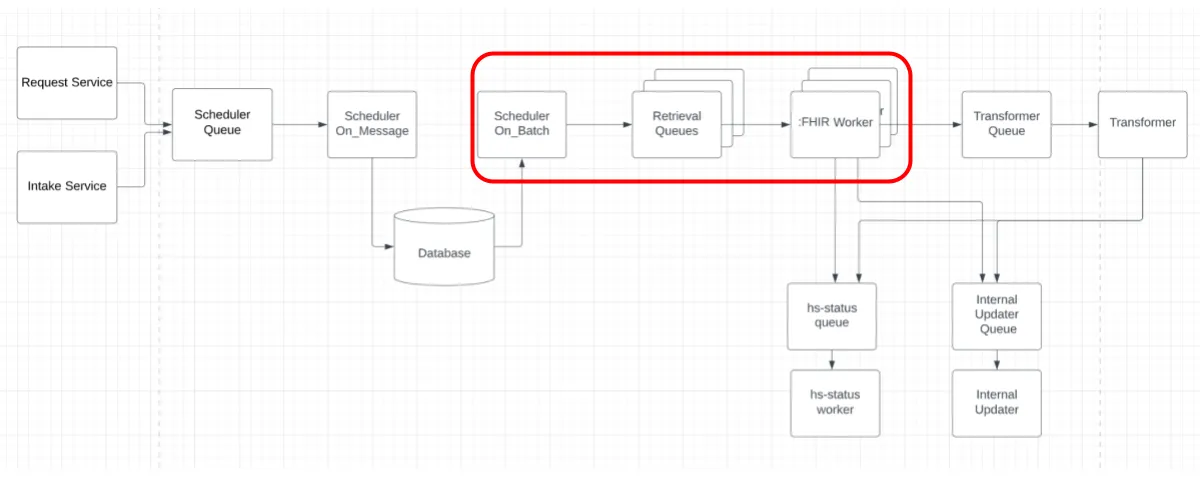
In our legacy system, record requests were accepted with our Request & Intake Services, dropped into a Scheduler Queue, then saved to a database by Scheduler On_Message. Scheduler On_Batch, as its name suggests, sent batch-by-batch requests to the corresponding Retrieval Queue. The corresponding FHIR Worker* listened to these requests to retrieve records.
*Sometimes our FHIR Workers are called EHR Workers because not all Electronic Health Record systems use the HL7 FHIR Standard…apologies if this creates any confusion. Trust us, we feel it too.
In this organization, every client (every hospital, EMR provider, etc.) has its own Retrieval Queue and dedicated FHIR Worker. As a result of this duplication within this part of this process, more clients equaled bigger bottlenecks.
After testing, we discovered that our FHIR Workers consumed patient search requests faster than the Scheduler could provide them. FHIR Workers completed the requests in queue and then idled, potentially for hours, waiting for more requests to arrive.

During the first runs of our person-based flow design, when ~500k requests entered the system, the Scheduler On_Batch process became a bottleneck. After 30—45 mins, Scheduler On_Batch had not cycled through all the queues and more retrieval queues slowed this process even further. This meant that we were not fully utilizing the provider API bandwidth and retrieval time was not as fast as the provider API would allow.
Reducing complexity, simplifying interfaces
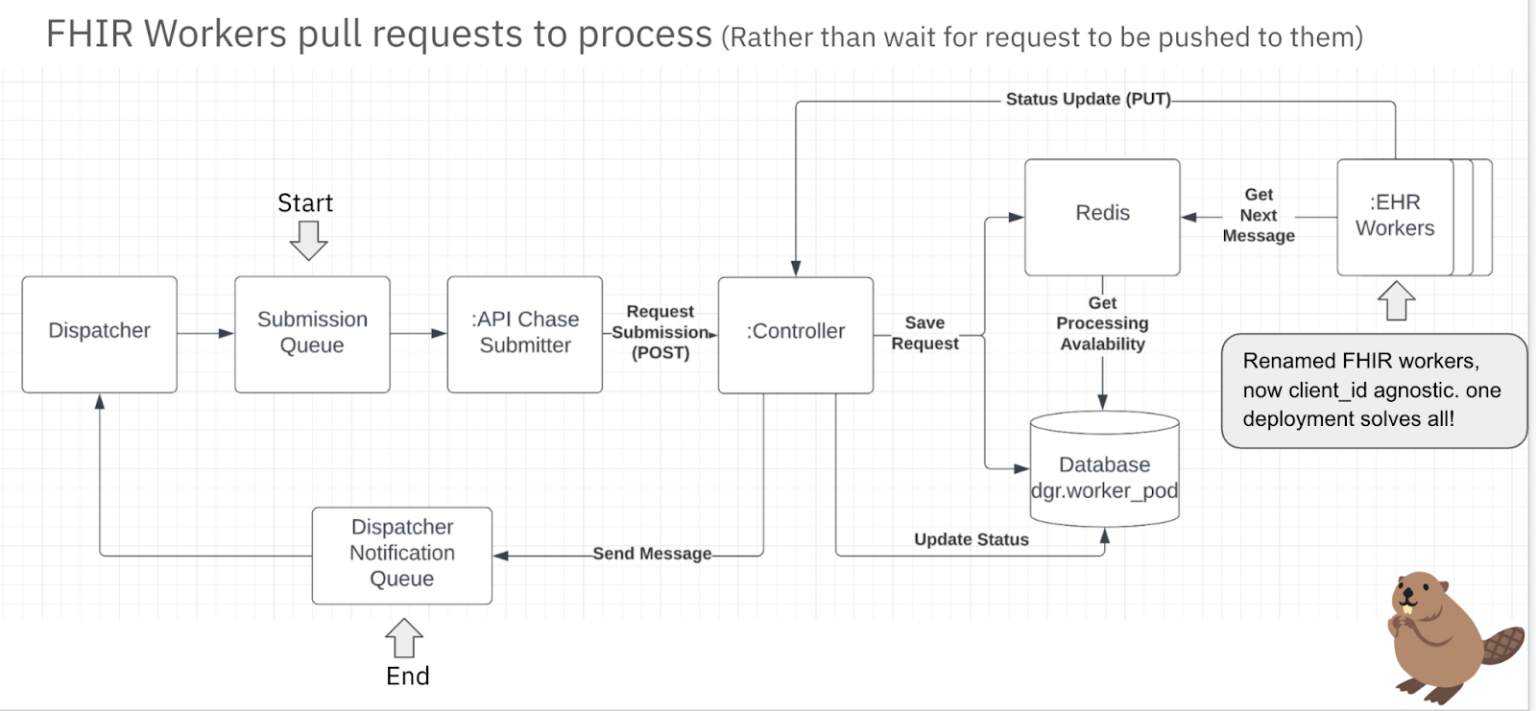
The biggest change in system design was to make FHIR Workers/EHR Workers actively pull requests to process rather than have them wait for requests to be pushed to them.
Requests are submitted to the Submission Queue by the Dispatcher, and the API Chase Submitter, which listens to the queue, and submits POST requests to the Controller, an API service that manages the lifecycle of requests sent to the provider API. The Controller populates a Redis Zset with requests and their associated processing priority. FHIR/EHR Workers pull requests to process from this Redis ZSet and, upon completion of the request processing, send update and retrieval results back to the Controller. The Controller then updates the request status and sends a message to the Dispatcher Notification Queue.
Redis Zset is a sorted set that holds a type of key and value.
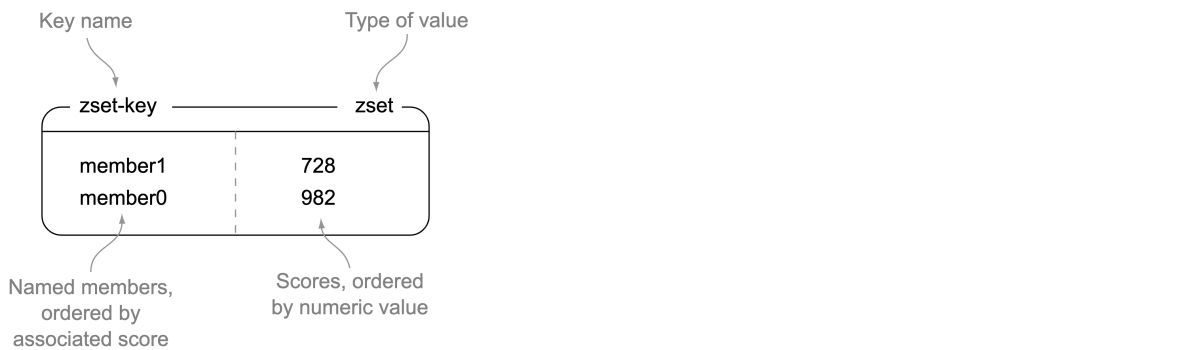
The keys (called members) are unique, and the values (called scores) are limited to floating-point numbers. ZSETs have the unique property in Redis of being able to be accessed by members (like a HASH), but items can also be accessed by the sorted order and values of the scores. To store requests in Redis Zset, the key/member is the request body JSON string and the value/score is the associated priority of the request. Requests are then sorted by order of priority.
Results of the redesign
The redesigned system processed significant at-scale loads in minutes that would have taken hours in the legacy system. (Under extreme circumstances, the legacy system could not run on its own and required human intervention to continue running.) Because the system is horizontally scalable, we can multiply this throughput with more pods and provider APIs. In addition to scalability, this redesign also improves efficiency and maintainability as it makes use of only one deployment of the FHIR/EHR Worker to handle API chart retrievals for all of the Datavant’s Identified Switchboard.
This essential component of the Switchboard creates a single request starting point and routes requests where they need to go – whether that be the health system, EHR vendor, or data aggregator – maximizing yield and minimizing turnaround time.
In other words, we’re beginning to chip away at the question,
“Why is it so hard to retrieve…?”
The API System redesign was driven by Sherry Liu, with support from Datavant’s Connection Pod and the IDSB team, including:
Victor Cai
Abhishek Goyal
Micheal Stensby
Aidan Higginbotham
Russell Kirmayer
Nola Gordon
Alec Ruiz-Ramon
Ryan Ma
Sherry Liu
Authored by Sherry Liu and Nicholas DeMaison, with input from Victor Cai.
About the authors
Sherry Liu has a background in system management and data strategy, and is a software engineer at Datavant. Connect with Sherry on LinkedIn.
Nicholas DeMaison writes for Datavant where he leads talent branding initiatives. Connect with Nick on LinkedIn.
Considering joining the Datavant team? We’re hiring remotely across teams and we would love to speak with any potential new Datavanters who are nice, smart, and get things done, and want to build the future tools for securely connecting health data and improving patient outcomes.

