
An Overview of Approaches to Privacy-Preserving Data Sharing
This post provides an overview of patient privacy-preserving technologies and is an update to the original post in August 2019.
Thanks to privacy technology thought leaders Abel Kho, Andrei Lapets, Dan Barth-Jones, Patrick Baier, and Ian Coe, as well as internal experts Aneesh Kulkarni, Jasmin Phua and Victor Cai, for their ideas and contributions to this post.
In my earlier post, The Fragmentation of Health Data, I gave an overview of where data comes from and how it flows across the healthcare ecosystem. This post will focus on the landscape of privacy-preserving technology and approaches to protecting patient privacy during those data flows.
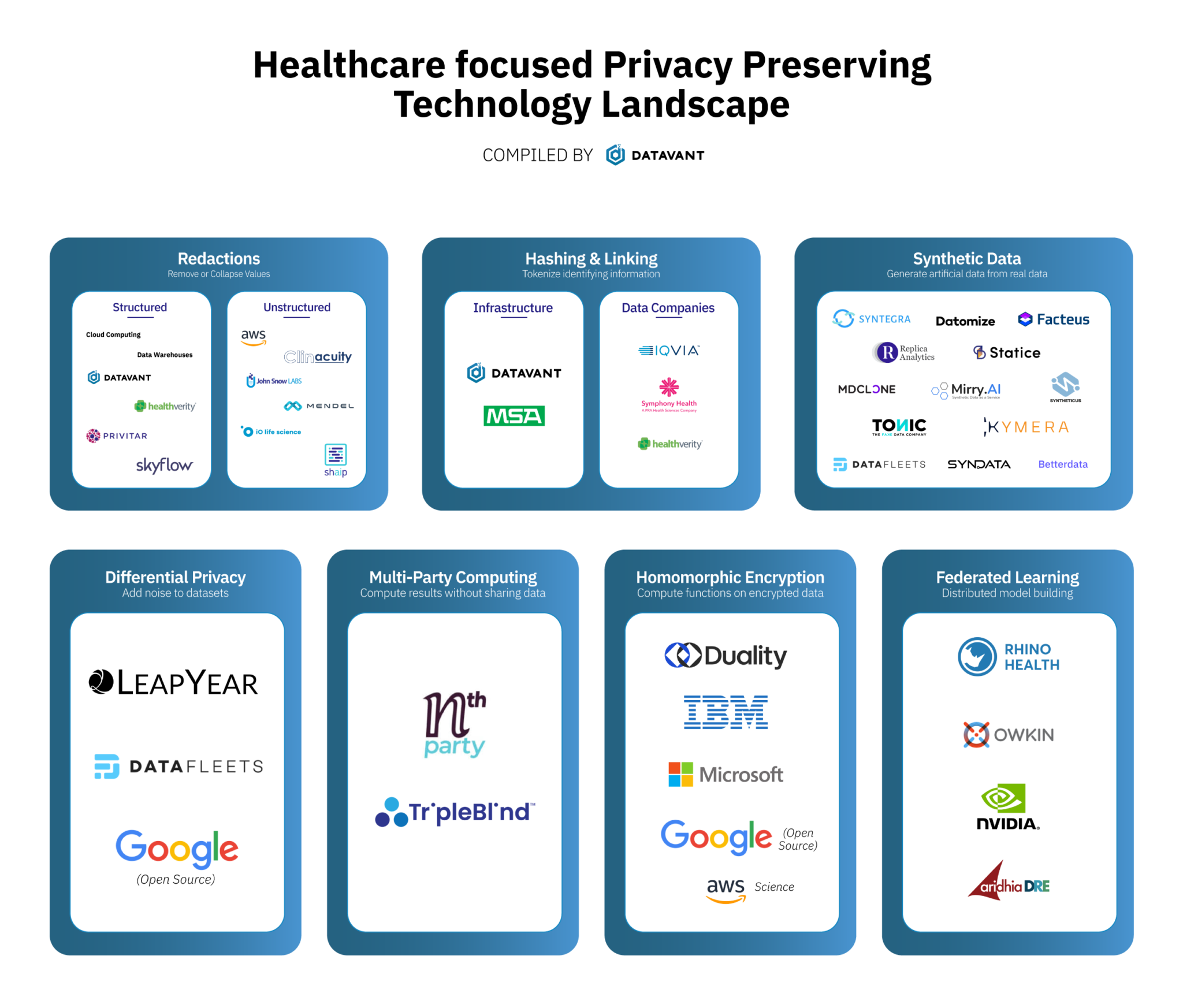
Don’t see your organization listed? Please get in touch!
In the US, millions of healthcare events take place every day, ranging from patients undergoing lab tests, to patients picking up prescriptions at a pharmacy, to patients passing away. There are many analytical and public health uses of this data, including:
- population-level statistics (“How many measles cases are there among 5—10 year olds in California”)
- discovering the effectiveness of treatments (“What is the 10-year survival rate of patients who take a particular drug?”)
- discovering adverse events (“Are cancer rates high among patients who receive a particular medical device?”)
- discovering new targeted therapies
Traditionally (and especially since HIPAA was passed in 1996), these analyses have mostly occurred on top of datasets that have been “de-identified.” Researchers are seeking an answer in aggregate, so they don’t need to know who a patient is – but they need the underlying health data about each patient to perform an analysis.
As more and more data becomes available, the pace of research relying on linked, de-identified health data has increased; but, at the same time, this has also made it harder and harder to truly anonymize patient information. This is causing a public debate around a tradeoff between the use of health data for analytical purposes and protection of data for a patient.
Three major factors are driving interest and investment in privacy-preserving data methods today. First, patients and institutional actors are becoming more concerned with privacy. Second, collecting, sharing, and utilizing patient data – and putting that data to use – continues to explode. And finally, the societal value and patient benefits of data-driven analysis and innovation continues to grow. Expect these trends to accelerate.
Approaches to Privacy-Preserving Data Sharing
So how does each technology work, how do they score on key dimensions and what should you be aware of? Below is a summary table. A description of each approach follows:
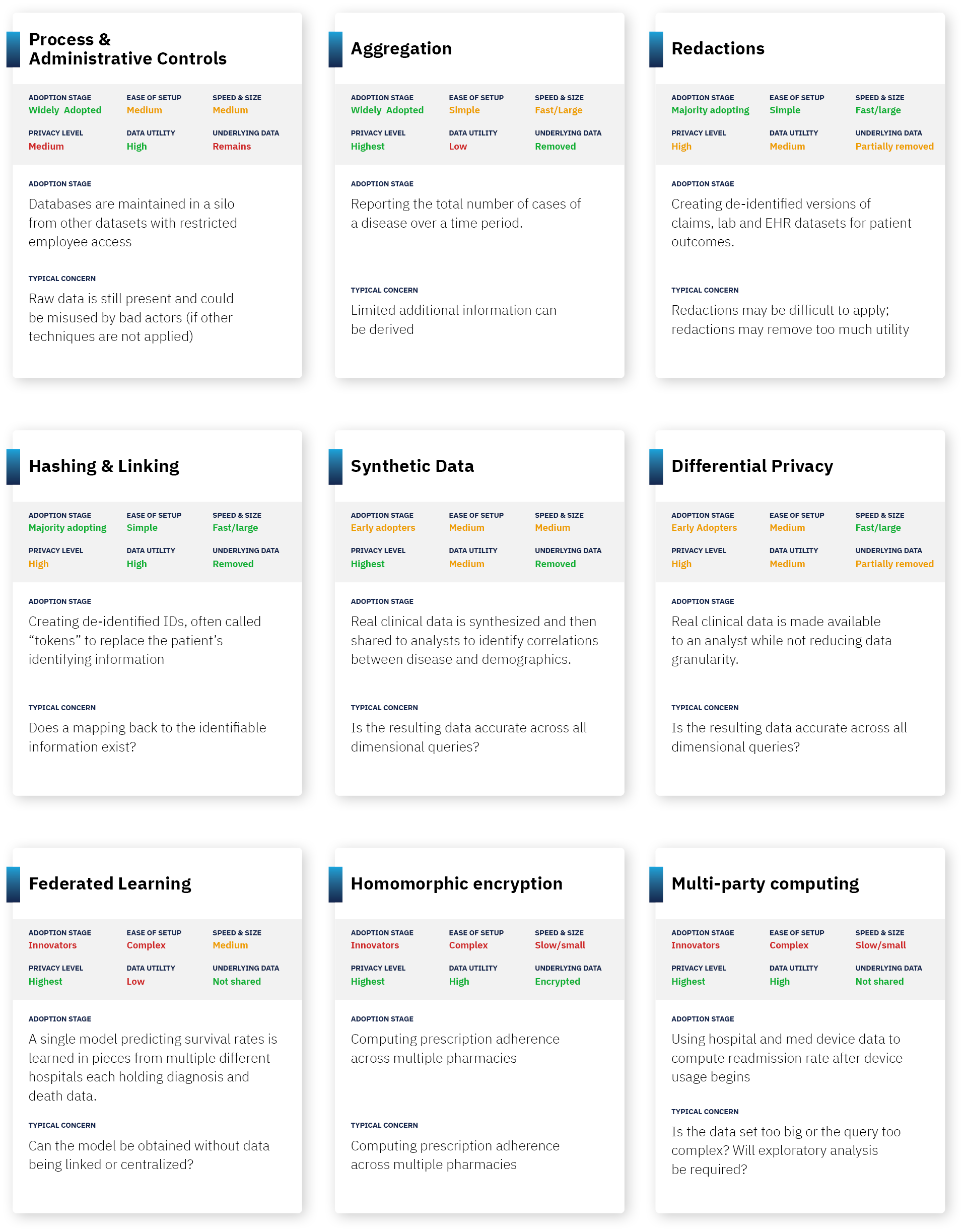
Approach 1: Process and Administrative Controls.
Summary: One fundamental form of ensuring that data stays de-identified is to ensure that anyone who has access to the data credibly agrees to not attempt to re-identify it. This can include internal firewalls (agreements that a party won’t combine data with other parts of the organization), audits, controlled access (for example, access to datasets by only certain individuals or access only in a “clean room”), and contracts. Another approach is Confidential Computing which uses a hardware-based execution environment to hold data which is hidden to users of the system, even while the data can be used in computations and producing results.
Pros: In most pragmatic use cases, process controls can ensure that data is only used for legitimate research purposes, and that the privacy risks of data exchange are theoretical vs. practical. Combined with other approaches (such as basic redaction), this can significantly reduce the likelihood of actual re-identification.
Cons: This approach leaves open the risk of bad actors or process failure that jeopardizes patient privacy. On the flipside, overly draconian process controls can delay research and reduce data liquidity. Finally, when controls are used by themselves, the underlying data is not actually de-identified.
Future: While not transformative, investment in security personnel and technology/tooling will grow.
Approach 2: Aggregation.
Summary: A simple form of de-identification is to store an aggregate answer, and then delete all underlying records. As a result, no data is individually identifiable as it is made up of many individuals and only produces totals (such as counts, averages or correlations).
Pros: This is a form of “true anonymization” – where all underlying data is removed.
Cons: This is only feasible for fairly simplistic research – it requires knowing a question upfront, and for the answer to that question to be in a single data set. It also removes data needed for substantiating research studies.
Future: Expect aggregated results to continue to be widely used and distributed.
Approach 3: Data Redaction.
Summary: This is the most common form of de-identification. Institutions start by redacting explicitly identifying information (eg. my name and social security number), then continue by creating categorizations (eg. birth year instead of birthdate), and then removing low frequency data from a dataset (eg. removing extremely rare disease patients from a data set).
Guaranteeing “K-anonymization” is a measurable form of redaction often used in HIPAA Expert Determination assessments. This approach requires that data is redacted or bucketed until there are more than K-1 records that look identical. So, for 100-anonymization, a record can only be preserved if there are 99 identical records, and redaction continues until that occurs.
Pros: Basic redaction is simple and has extremely high impact at reducing pragmatic privacy risk; for example, removing name and social security number is an obvious first step on any data set. It is also relatively straightforward to specify and test what conditions should be met.
Cons: Data redaction can remove valuable information that is useful for analysis. This is especially true for machine learning approaches (where having lots of data is valuable), and this is also very true if data is strictly k-anonymized. For example, a date of service and a diagnosis code can be valuable for computation, but these two data attributes may need to be redacted as “indirect identifiers” depending on the strictness of the de-identification. In addition, as more datasets are combined, the redactions become more complex and more stringent.
Future: Expect this to continue to be a widely used method for years to come. Also expect technology to improve the precision and reliability of redactions, making the privacy guarantees from this approach stronger.
Approach 4: Hashing & Linkable Redaction (or, “Pseudonymization”).
Summary: A cryptographic approach known as hashing can be used to indicate whenever two data attributes are the same, without knowing what the underlying attribute means. For example, “Travis May” could match to a consistent hash value “abc123”, which means that whenever that shows up in the multiple data sets, a researcher can know that it’s the same patient, without knowing being able to reverse engineer that “abc123” corresponds with “Travis May.”
Pros: This can solve for redacting identifying information, but while allowing data to be linked across data sets – an important component of any major research study. This method is also specifically approved under HIPAA as a means of de-identified linking (though linked data sets still need to be reviewed for whether the combination of data is itself too identifying).
Cons: Careful key management and process controls must be created to ensure no party can build a “lookup table” or otherwise reverse engineer hashes. Additionally, hashing is only useful for true identity aspects (such as name), but is not useful for de-identifying the attributes about a patient.
Future: as more data sources and types become available, more questions will become answerable through privacy-preserving linkage and the value and use of this technique will grow with it.
Approach 5: Synthetic Data.
Summary: Synthetic data is data that is generated to “look like” real data, but not contain any actual data about individuals. This can be used most frequently as a way to test algorithms and programs.
Pros: No actual data about individuals is in the data set used for analysis, so there is theoretically no privacy risk. Meanwhile, most statistics about the data can stay intact (averages, correlations of different variables, etc.)
Cons: While you can synthetically create data that maintains basic summary statistics, nuance in the data can be lost that is relevant to machine learning approaches, targeted quality improvement projects (e.g., identifying at-risk populations for whom you want to improve a particular process), and effective clinical trial recruitment. Also, synthetic data approaches don’t allow you to combine data across datasets about the same individual (which is often necessary for longitudinal analysis). Also, approaches generally require knowledge ahead of time what statistical query you want to ask.
Future: Expect an increase in investment leading to improvements in the ability of synthetic data to support a wider range of complex queries with increasing fidelity to the underlying data. As this happens, this technology will rapidly move up the adoption curve as it offers the promise of non-redacted data and strong privacy.
Approach 6: Differential Privacy.
Summary: Differential privacy is an approach in which “random noise” is added until it becomes technically impossible to identify any individual in a dataset. For example, within an underlying record, a date might be shifted by a few days, a height might be changed by a few inches, etc.
Pros: Adding random noise can often be less destructive of information than redaction of data to get a similar level of anonymization.
Cons: Differential privacy is computationally complex to do at scale in a way that achieves the desired privacy guarantees while keeping the analysis useful. Some data sets (unstructured data, for example), do not work at all in a differential privacy context. [This is a cutting edge approach which means the cons may be significantly reduced in coming years]
Future: Expect to see differential privacy deployed in pockets as a method of stronger internal controls for users of a system, as well as a method to make unique data types like genomic data available for de-identified research.
Approach 7: Multi-Party Computing.
Summary: Multi-party computing is an approach in which an analysis can be done on several data sets that different organizations have, without the organizations needing to share the data sets with each other. You might think of this as bringing the analysis to the data rather than bringing the data together for analysis. For example, if a pharmacy knows which drugs were filled, and a hospital knows what drugs were prescribed, multi-party computing can be used to determine what percentage of patients fill their prescriptions, without either party sending patient data to the other. This uses a variety of cryptographic approaches to ensure that no party gets access to more information, except the aggregated answer.
Pros: Can drive valuable analysis without privacy loss. In theory, any analysis can be done in this form.
Cons: Computationally complex and still emerging as a field, meaning computers struggle to run these algorithms quickly and they are difficult to build. Protects inputs and intermediate values in a computation, but outputs may still reveal identifying information (and thus approach can be augmented with differential privacy or another technique). [This is a cutting edge approach which means the cons may be significantly reduced in coming years]
Future: Expect investment to create steady gains in computation speed and ease of deployment leading to real-world viability. However, do not expect overnight breakthroughs or rapid adoption.
Approach 8: Homomorphic Encryption.
Summary: Homomorphic encryption is an approach in which mathematical operations can be done on top of encrypted data. This means that an algorithm can be performed against data, without actually knowing what the underlying data means. For example, if a hospital knows the date of prescription, and a pharmacy knows the date the prescription is filled, homomorphic encryption would allow a company to find the time elapsed in between those two dates without knowing the underlying dates.
Pros: Can drive valuable analysis without privacy loss. In theory, any analysis can be done in this form.
Cons: Similar to the cons of multi-party computing, homomorphic encryption is also computationally complex and still emerging as a field, meaning computers struggle to run these algorithms quickly and they are difficult to build (to give a sense, homomorphic encryption is estimated to be >1M times slower than running computations on raw data). Protects inputs and intermediate values in a computation, but outputs may still reveal identifying information (and thus approach can be augmented with differential privacy or another technique). [This is a cutting edge approach which means the cons may be significantly reduced in coming years]
Future: Again, similar to multi-party computing, expect investment to lead to slow but steady progress in computation speed and limited real-world viability. Do not expect overnight breakthroughs or rapid adoption.
Approach 9: Federated Learning
Summary: Federated Learning enables a model to be created from disparate datasets that are never physically present together. In short, the model goes to the datasets to get trained, the pieces get sent back to the control center, and the weights are combined into a single model that can then produce answers or be deployed on other datasets.
Pros: Enables learning from many datasets without requiring data to leave the data owner’s four walls.
Cons: Does not work well when individual records or datasets across contributing organizations need to be assessed together (such as for cross-organization record linkage). In addition, the model itself must be visible to each data owner.
Future: This has the potential to unlock data usage in the growing longer tail of data sources who want to contribute data for research purposes they approve of, but who may have constraints to physically releasing even de-identified data. In the United States this long tail is large and necessary for a complete view of the patient.
***
Of course, in addition to privacy-preserving technologies, patient consent can and should often be used to engage the patient in the decision to use data that is initially about them. While getting consent can be administratively challenging, researchers often find that patients are remarkably generous with their data if it can help other patients like them.
In practice, every organization should practice data minimization (i.e. redacting or walling off data that isn’t necessary for analysis (like social security numbers at an extreme!)), smart administrative controls, reasonable patient consent (depending on the use case), and some combination of other methodologies. The use and value of each of the technologies currently being developed will be accelerated by advancements in the ability to automatically measure and reduce risk in datasets, leading to a more reliable, higher quality and faster HIPAA Expert Determination processes.
With all these different methods and approaches to privacy-preserving data sharing, at the end of the day, the most important guiding principle is to do well by the patients who entrust institutions with their data.
As the amount of data continues to explode, as the societal value of data-driven analysis continues to grow, and as individuals become more concerned with privacy, expect lots of continued research in approaches to privacy-preserving data methods.
***
An Overview of Approaches to Privacy-Preserving Data Sharing was originally published in Datavant on Medium, where people are continuing the conversation by highlighting and responding to this story.
Editor’s note: This post has been updated on October 18, 2022 for accuracy and comprehensiveness.

