
The Fragmentation of Health Data
A Survey of The Health Data Ecosystem
At Datavant, we’re focused on the vision of connecting the world’s health data to improve patient care and speed the development of new treatments. As part of this, we put together an “ecosystem map,” outlining how data flows across healthcare today.
***
Updates (September 2019 & September 2021): Since publication, we’ve seen copies of this ecosystem map show up at conferences, in classrooms, and in boardroom discussions – and have had hundreds of requests for the underlying graphic and lists. Given the traction, we feel an obligation to make sure that the map doesn’t go stale. To that end, we’ve prepared a new and expanded health data ecosystem map below. The size of the health data ecosystem has grown significantly in the past year. There are many new logos and the amount of health data in existence has more than doubled.
***
The healthcare system generates approximately a zettabyte (a trillion gigabytes) of data annually, and this amount is doubling every two years. The scale and distributed nature of this data presents an enormous challenge for those seeking to understand health data. Yet as the scope of this challenge keeps increasing, so does the potential to use data to define and deliver value for patients across the healthcare system.

The ecosystem around this data is complex, with thousands of institutions involved in the collection, transfer, and use of healthcare information about patients. This post gives an overview of how data flows through the healthcare system in three sections.
- The first describes how patient health data is generated in the course of a patient’s interactions with the medical system.
- The second focuses on the intermediaries that currently house, exchange, and organize this data for analysis.
- The third briefly address how the system currently addresses data security and patient privacy: how to ensure the right data is in the right hands at the right time.
[A follow-up post will talk about how the data is ultimately used to help improve patient care, as well as a deeper discussion how data is protected throughout the process.]
Part 1: Health Data Generation and Exchange
Each interaction that a patient has with the healthcare system generates many data points, which are likely held by several different institutions. Data from everyday activities also provide valuable information about a patient’s health. Regardless of where the data is generated, institutions usually collect data to meet an operational need rather than to power analytics. As a result, data is fragmented (and sometimes duplicated) across many institutions and data capture systems.
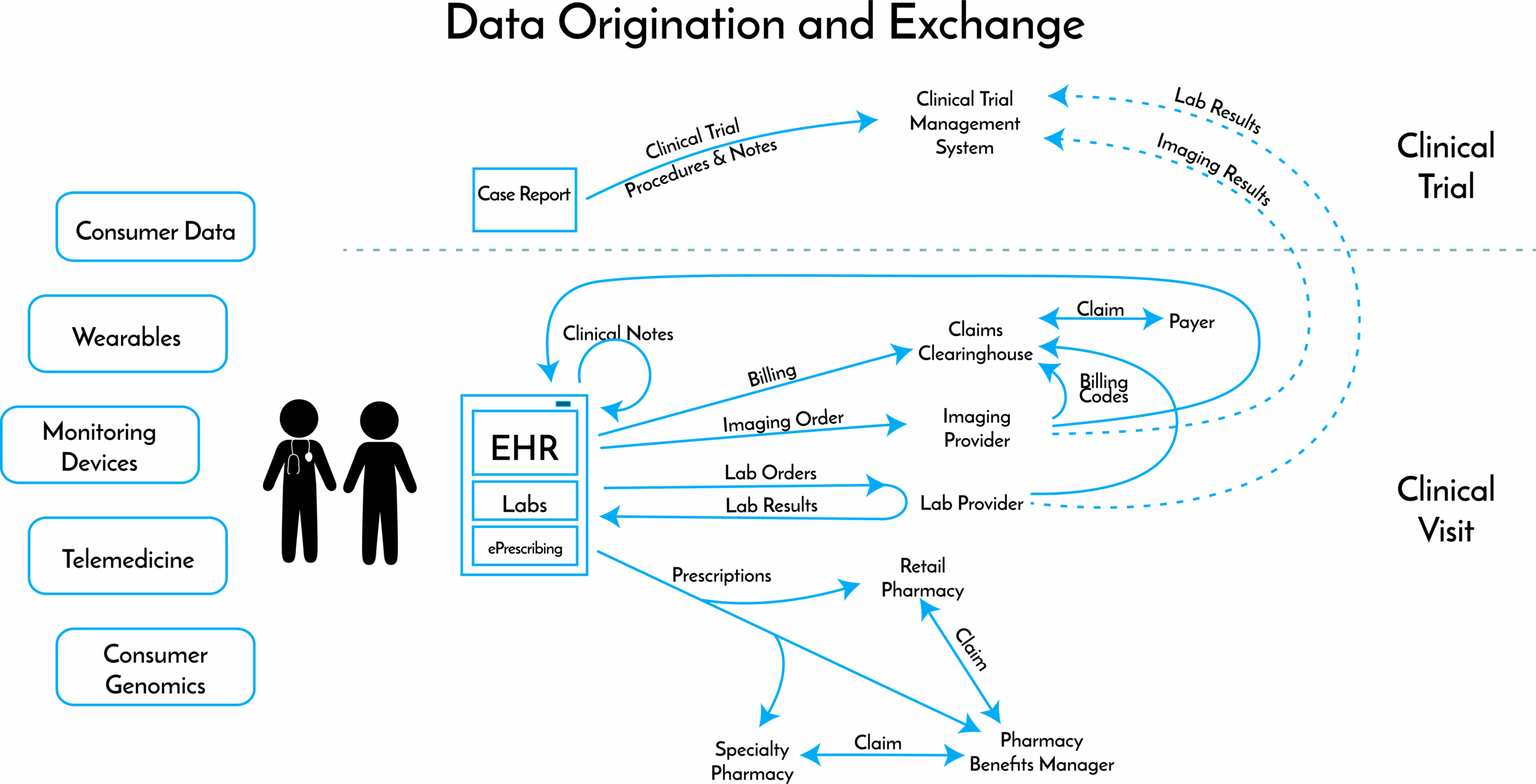
To illustrate the data that is generated by a single patient visit, let us follow the hypothetical case of patient Jane Doe. Jane has been seeing her primary care doctor for years and goes in for a routine check-up. Over the course of the 8—12 minutes of face time that she spends with her doctor, a number of different data elements are generated. Jane’s doctor:
- Enters clinical notes from the visit into the practice’s electronic health records (EHR) system. The doctor completes structured fields (type of visit; services and procedures performed; Jane’s diagnoses), and provides free text offering additional context.
- Orders a panel of standard labs. The doctor enters both the order and the lab results into the EHR.
The EHR’s billing module then prepares an insurance claim for Jane’s insurer. The draft claim is sent to a clearinghouse that checks the draft for errors, reformats the claim to match the insurer’s standards, and then sends the claim to the insurer.
Only a small subset of a patient’s health is determined by clinical care. The other drivers are behavioral, social, economic and environmental. Some of this data is captured in medical records. For example, knowing Jane’s address provides some socioeconomic detail, and could be used to gather information on proximity of services, as well as air and water quality. However, most non-medical data is not captured as part of health analysis. Relevant information might include:
- Genomic data from an ancestry test she took last year that provides information on genetic predispositions;
- A fitness tracker that Jane wears capturing data on her physical activity;
- Credit card and loyalty card records capturing Jane’s purchasing behavior (grocery purchases; over-the-counter meds; cigarette purchases);
- Large consumer data providers collect information on Jane that is used for targeted marketing purposes (income estimate; taste in consumer products; subscriptions);
- Social media platforms capture data on Jane’s behavior (likes; check-ins; group memberships; information consumption);
This year, Jane is due for a mammogram. Her doctor sends her to a local radiology clinic. The radiologist:
- Captures clinical notes and billing information in the radiologist’s (separate) EHR;
- Generates and stores imaging tests, revealing that Jane has a tumor in her breast (Jane is given the results on a CD to take to future doctor’s appointments);
- Relies on the EHR billing module to compile an insurance claim, which is sent to a clearinghouse and on to Jane’s insurer.
After receiving her diagnosis, Jane proceeds to see a number of specialists for further analysis and treatment, each visit generating its own record in that doctor’s (again, separate) EHR system. If Jane is fortunate, her doctors will be able to exchange information with one another through an interoperability platform. More likely, her information will be shared via faxes and print-outs.
One oncologist sends a prescription for a targeted therapy to a specialty pharmacy, which dispenses complex medications and provides services to educate patients and help them with side effects. The oncologist also prescribes medication to manage side effects; those prescriptions are sent to Jane’s local retail pharmacy. Each pharmacy separately generates data on pick-ups and refills, and compiles insurance claims for the pharmacy benefit manager (PBM) that administers the prescription drug component of Jane’s health plan. The PBM processes and pays the claims.
Unfortunately, Jane’s condition progresses. Her oncologist advises her that she may be eligible to enter a clinical trial for a new therapy. Jane elects to do so and is able to participate after clearing the inclusion and exclusion criteria for the trial. Now, when Jane visits her oncologist, staff enter Jane’s data – notes from her visits, labs, images – into two separate systems: the oncologist’s EHR, and a clinical trial management system (CTMS) as a structured Case Report Form (CRF). Jane’s data will later be used in analyses detailed in the trial protocol that will inform whether the new therapy will be approved for sale.
Part 2: How Health Data Flows through Intermediaries to Improve Care
As patient health data has proliferated at an increasing rate, industry players have focused on harnessing this data through analytics to improve treatment options, enhance patient outcomes, streamline operations, and move toward a value-based care paradigm.
The first step toward performing valuable analytics is ensuring that the right data ends up in the right hands at the right time. Current aggregation strategies address aspects of this challenge, but as the data ecosystem becomes increasingly complex, new approaches are needed.

As we saw in Jane’s story, systems used to generate health data are designed for operations, not to organize data effectively for research or analytics. To facilitate analysis, companies and organizations have pursued several strategies to aggregate different data sources and data types:
- Enterprise Data Warehouses (EDWs) are often implemented at large healthcare organizations with the help of professional systems integrators. They house and organize internal data, as well as data purchased or collected from outside the organization. EDWs facilitate analytics at the institution level, but they are not designed to capture or link data across the many organizations that generate data in the course of patient care.
- Data Aggregators gather, de-identify and then sell patient data pulled from many organizations. Aggregators provide services to data originators, including benchmarking of quality measurements and business processes against other similar institutions and group purchasing of supplies and equipment, and in return are granted access to their data. Since each aggregator works with a different set of data originators, one patient’s data may end up duplicated or spread across multiple aggregators. Most aggregators have built broad datasets from one type of originator (e.g., claims or hospital visit records) and join other types of patient data to build more comprehensive record sets. While the data types an aggregator has on a given patient may not be comprehensive, each major aggregator has records on tens of millions of unique patients in its database.
- Patient Registries build and maintain databases of patient information on specific, clinically-relevant populations to support research and improve care outcomes. Registries may be compiled by government entities, patient advocacy organizations, hospitals or integrated delivery systems. The goal is to compile clinically-rich, curated datasets, which may also include socioeconomic and behavioral data. In order to do so, organizations need to define data standards, address interoperability and data-linking challenges, build adequate technical infrastructure, and ensure there are sustainable methods of patient data collection in place.
- Government Agencies serve as both data originators and aggregators in several different capacities. The Veterans Administration health system provides care for more than 9 million American veterans each year. More than 100 million Americans rely on Medicare, Medicaid, and other federal programs for health insurance. The Centers for Medicare and Medicaid Services (CMS) have aggregated Medicaid and Medicare claims data, which qualified entities can access for analytical and research purposes. Separately, in an effort to have a comprehensive view of utilization, a number of states have established All-Payer Claims Databases to collect claims from all of the major health plans operating in their state.
Analytics meant to measure or improve the care received by someone like Jane require visibility into multiple data types generated across a number of different touchpoints with the healthcare system. Each of these aggregation strategies does the hard work of bringing together data from some part of the complex landscape of healthcare data. New strategies to link datasets together will likely emerge as the volume and variety of data relevant to health continue to increase and analytics groups look to incorporate these data into their use cases.
Right Data, Right Hands, Right Time
This large ecosystem of data stewards, aggregators, and service providers strives to make the healthcare system better – informing timely interventions, developing innovative medical products, and reducing operational and financial friction. To empower this ecosystem in the face of its complexity, the industry will need to take steps to ensure that the right data ends up in the right hands at the right time.
“Right data” means the specific data elements about Jane’s health from all relevant sources (not just those immediately available) are linked together to power a given application. As demonstrated, healthcare data is generated in many forms among many entities, through both clinical care and everyday life. Each analytical solution will need to curate a different combination of elements to work effectively, linking data from across the care continuum.
“Right hands” means that Jane’s data can be securely transmitted from each source to the authorized analyst while maintaining Jane’s privacy. The complexity and sheer volume of the data ecosystem mean that patient privacy and data security are among the most pressing issues facing organizations trying to bring healthcare data together. From a legal perspective, HIPAA, GDPR, the new California Consumer Privacy Act, the FTC’s data privacy enforcements, and similar legislation and regulatory bodies provide much of the regulatory framework for how data is used. For research purposes, IRBs are also instrumental in determining the appropriate use of data. From a first principles perspective, institutions throughout the health data ecosystem must ensure the patient value of each data use case, the security of data throughout the system, patient consent and access, permissions for secondary use, and avoid risks of data leakage.
“Right time” means that this data exchange can happen with minimal friction, so that the data can be assembled and queried in time to make a difference. It should be easy for an internal analytics group, consultant, or startup to collect the data it needs to power a use case. Mechanisms that connect different datasets and give visibility into how they overlap will need to be built in order to make this a reality.
As the amount of data continues to expand and the sophistication of analytics becomes richer and richer, we expect the complexity of the ecosystem (and the stakes around some of the issues facing the ecosystem) to continue growing exponentially in coming years.
***
Primarily Authored by Jacob Stern. Special thanks to Andy Coravos, Sebastian Caliri, Samuel Bjork, Colby Davis, Eric Perakslis, and Shahir Kassam-Adams for reviewing early drafts.
Editor’s note: This post has been updated on October 18, 2022 for accuracy and comprehensiveness.

