Why the New Interoperability Rules Don’t Yet Mean the Death of the Fax Machine
In a 2018 piece on why American medicine still runs on fax machines, Vox explained why the last decade of US government efforts to automate health data exchange had shown limited results. Earlier this month, new rules from ONC and CMS went into effect focused on making it easier for patients to access their health information and to exchange data across electronic health record systems and payers. Here, we explain why the fax machine continues to be such a formidable opponent.
Getting access to your health information isn’t easy
To understand the great staying power of the fax machine, consider the experience of a patient Jane Doe, who decides that she would like to access her health data. Like most of us, Jane changes jobs every few years, and as a result she’s been on a number of different health plans, each of which stores her records in their own systems independently. She has also moved around a few times for school, then work, and then to be closer to family. In each of those locations, she had a primary care provider, but also had a couple hospital visits and had to see a number of different specialists, from her gynecologist to her ENT.
Jane’s first option is to pull the records herself. To the best of her recollection, she compiles a list of all the encounters she has had with the healthcare system over the years. She then decides to see what’s available online and is pleased to find that her current primary care provider is affiliated with a health system that offers an online patient portal. However, several of the specialists she is seeing aren’t in the same portal, and she can’t find a way to log in to similar portals for providers she’s seen in the past. She knows that she’s on a Blue Shield plan now and used to be on United, but she can’t remember before that.
Jane decides to start working the phones. She calls her gynecologist’s office, who tells her that they can export a PDF and send it over to her in a few days. She has a few similar calls, with some people offering to send her PDF exports, others offering to scan in documents, and others asking her for a fax number. Others are non-responsive or have a formal request process, which might require Jane to send a written request letter or, in extreme cases, to go to the provider site to make the request. Months later, what Jane is left with is not a unified set of her medical records, but an incomplete mix of login credentials for different portals and PDFs in her email that she will have to organize and categorize herself.
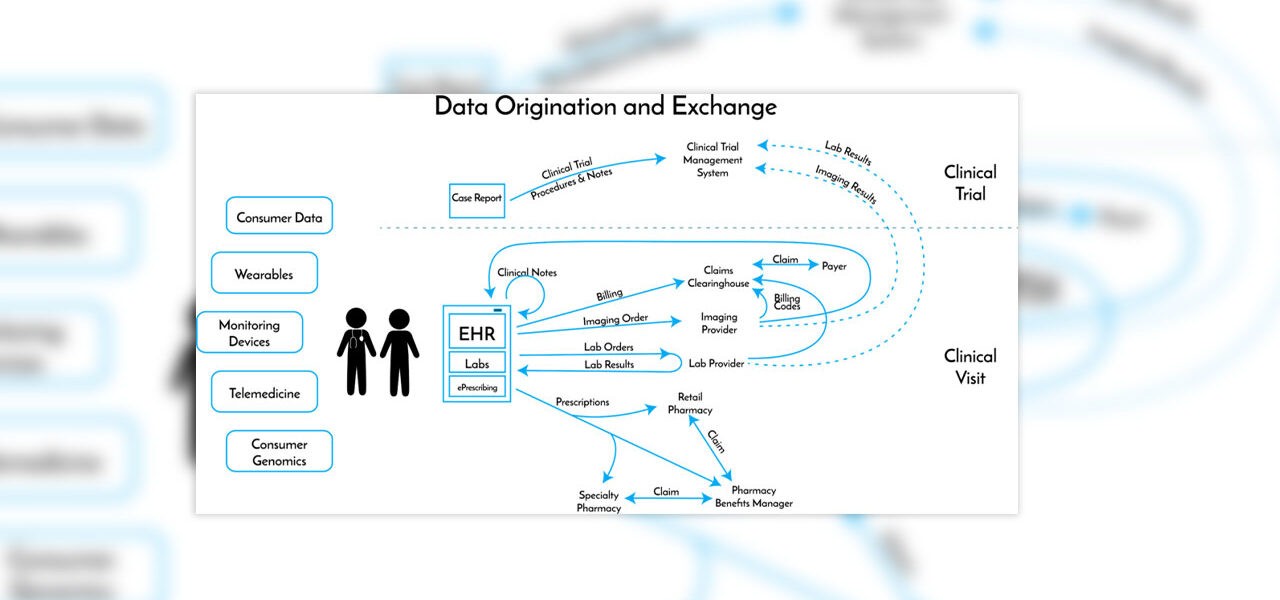
And of course, every individual interaction with the healthcare system touches lots of different data repositories, few of which are integrated:
And making information requests easier is a big operation
In practice, this process is laborious enough that patients and their representatives (lawyers, insurers, etc.) work with specialized companies to go pull medical records, and providers work with other companies to ensure they are fulfilling the requests promptly and in a compliant way. A number of companies exist to solve for different parts of the process:
- Intake. Requesters need a simple way to make a request. While a number of companies streamline this part of the process, requesters still have to provide a version of the initial list that Jane compiled so that the company knows where to look for records.
- Fulfillment. As Jane found when she tried to pull her records herself, getting access to records will require a mix of logins, emails, calls, letters, and even onsite visits. Companies that want to fulfill Jane’s request need to provide not only a portal and application programming interface (API) to pull information automatically where possible; they also must have call centers and employees embedded full-time at provider sites. Those employees might enable a request to be fulfilled by logging into the EHR on the provider’s behalf and printing, scanning, and faxing or uploading the necessary records.
- Quality Control. Part of the challenge for providers is ensuring that they are providing the right records to the right requester. Sending out the wrong patient’s records can result in privacy violations and fines for the providers. Companies that facilitate this process have trained specialists checking that they have pulled and are providing the right records, and that all necessary authorizations are in place.
- Distribution. Once the records have been pulled and gone through a quality process, they have to be served back up to the requester.
Who is trying to fix the problem
There are four major classes of companies working to solve the problem of pulling patient medical information in a timely and compliant way:
- Patient-facing portals seek to make the intake process easier for patients. They offer one streamlined way of making requests and on the back-end, fulfill certain requests themselves and work with others to fulfill the rest. Portals may be affiliated with a specific provider organization or EHR, or seek to allow patients to pull all of their medical information in one place (e.g., Ciitizen, Picnic Health).
- API companies build application programming interfaces (APIs) that enable integrations with electronic health record and payer systems and allow data to be pulled automatically by patient or, more frequently, other developers building applications for patients. The two challenges are (i) developing APIs that can pull enough information to satisfy requests (including clinical notes and other unstructured information), and (ii) hooking them up, which involves convincing electronic health record vendors and provider organizations to use the API. The new ONC rules require the proliferation of APIs and many companies are working to solve the problem (e.g., 1UpHealth, Commure, Health Gorilla, Moxe, Redox).
- EHR companies are increasingly making data exchange easier between different organizations that use their systems, but a typical health system runs more than ten different EHR systems. There are different standards bodies and organizations focused on making it easier to exchange data directly between EHR systems (e.g., CareQuality, CommonWell), and most large EHRs belong to one or more of these organizations (including Epic, Cerner, AllScripts, etc.). However, we’re still a long way from a patient accessing their information in one EHR system and having that seamlessly pull in complete, corresponding records from other EHR systems.
- Record retrieval companies focus on filling in all of the remaining gaps. These companies may offer their own APIs, but they are also the organizations that will embed on-site personnel and run call centers if that is what it takes to pull patient medical records. While many startups frame this as the legacy way of doing things, the startups themselves are also highly reliant on these companies to do the high-touch last-mile operational work of fulfillment (e.g., Ciox, Change, Inovalon, MRO, Verisma).
Why the fax machine will outlive the new interoperability rules
There are a number of new interoperability rules currently being proposed and implemented, but the rules that went into effect on April 5th have two specific requirements:
- API Access: Over the next few years, health insurers and EHR vendors need to make the electronic health information that they hold available via an API according to commonly accepted data standards.
- No Information Blocking: The new rule also prohibits discouraging or impeding the exchange of electronic health information (a practice known as “information blocking”). The concern is that providers and EHR vendors have a commercial incentive to restrict access to patient data because having data only within their systems makes it harder for patients to switch organizations.
The new rules will make retrieval of some patient data more automated, and will make it much easier to develop new patient-facing applications that require access to patient’s data. However, the data that must be made available under the standards (the United States Core Data for Interoperability standards, or USCDI) is limited. The standards include structured data points like patient vitals, prescriptions, tests performed and lab results, but don’t include other valuable information, including much of the unstructured data that exists in a patient record.
Many valuable uses of patient data require access to the full record. Below is a brief summary of how many necessary elements the data standards cover for different use cases:
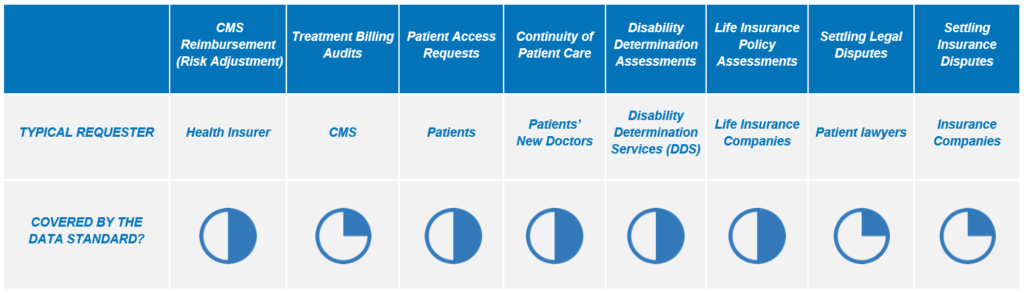
To take one example, risk adjustment (the process of determining what payment should be made to a Medicare Advantage plan for taking care of high-risk or high-cost patients) requires access to scans and test results, which won’t be available through an API.
The new interoperability rules will undoubtedly have positive impacts across the industry, and it is a good start. The change will improve patient access to health information, and allow patients to play a more direct role in their care. But because so much critical health information exists outside the data standard, we will continue to use scanners, call centers, and – in extreme cases – have people knocking on the door of a provider in order to obtain their records. And we will continue to fax.
What the future looks like
Today, the fragmentation of health data is the single biggest bottleneck to realizing the power of health data and technology to improve patient outcomes. Ten years from now, each of the following things should be easy and fast to do:
- Patients can log into an application of their choosing and seamlessly pull their complete health information from across insurers, providers, labs, genetic testing companies, and health and wellness applications within minutes.
- Physicians can pull data from one electronic health record system to another, and have that data summarized and synthesized so that the most salient information is easy to locate and process.
- Research organizations and life sciences companies can rapidly build new patient registries on top of de-identified data, accelerating our understanding of disease and the pace of drug development.
- Risk-bearing entities and provider organizations can frictionlessly exchange patient data to design systems of quality control and value-based care.
- Entrepreneurs and technologists no longer see access to patient data as a constraint, and focus on value-added capabilities on top of patient data, giving patients the same number of choices that they have for budgeting or dieting applications.
- Patient consent, compliance and privacy are built programmatically into all of these health data flows, offering a secure, federated architecture for the exchange of patient data and reducing the risk of privacy breaches across the industry.
The new rules are helping to point the way and resolve some coordination problems across entities, but it is up to the broader healthcare community to relentlessly pull this future forward.
***
Many thanks to Niall Brennan and Quinn Johns for their thoughts & feedback on this write-up.

