
The Fragmentation of European Health Data

The categories we show above are just a fraction of the different silos holding health data, from registries, government agencies, pharmacies, or clinical trials and adjacent data, to name a few. Datavant has written in-depth on the fragmentation problems characterizing healthcare systems — this snapshot is our first publication specifically on the growing European health data ecosystem1. Here, we focus primarily on clinical health data, and future publications will expand on this map of the ecosystem, including different modalities, use cases, and geographies within Europe.
Real-world data (RWD) is collected and stored heterogeneously and goes through a long process to become trusted, enriched, and integrated enough to be used by decision-makers in the health system. The data flowing through the RWD processing companies shown above is used to provide patient care, research health outcomes, and develop new treatments and therapies.
RWD processors are a growing and significant part of the European health data ecosystem. These companies establish relationships and pipelines with sources of health data — for example, the providers of healthcare, such as hospitals, clinics, or pharmacies — and gather, curate, and structure their data. RWD is often messy and complex, and the work of quality control and structuring into an industry-standard data model, such as OMOP, is a significant uplift to the data. Aggregators may provide services back to their data source partners, by way of improved management of their own data or benchmarking. Ultimately, aggregators prepare and secure health data to support research done by other institutions.
- Some data aggregators focus deeply on Electronic Health Records data only, bringing to light detailed patient journeys from complex hospital records. For example, these companies might focus on a particular therapeutic area with complex data, such as oncology or mental health, or a specific use case, such as selecting the right sites to launch a clinical trial.
- Another way to build an enriched view of patient health is to pull together data from a wide variety of data sources, or modes of data. Multi-modal aggregators incorporate data from EHRs, pharmacies, social determinants of health, mortality, labs, consumer information, and more, working to stitch together a patient’s health experience across different aspects of their life that are not typically reconciled in hospital or primary care data alone.
- Imaging, genomics, and other “unstructured” data are often processed and aggregated separately from other modes of data. Unique collection pathways, often in separate software from other health records, and unique privacy considerations characterize this data silo.
- Mortality registries can serve many other needs outside of health research; a key differentiator is accompanying information describing the causes of mortality, as well as the dates and other facts of the event.
- EHR systems create and maintain software that healthcare providers use to store and manage health information, but some may also build tools and services that allow that data to power insights or other services, such as connecting patients to opportunities to find specialized or novel clinical care.
This ecosystem of custodians, aggregators, and researchers operates to make the health system better and more effective for patients and providers. Each time a processor collects data from various sources, or a researcher collects data from aggregators, the health information must be passed to trusted people and securely into trusted systems. Tokenization connects disparate health data across stakeholders (e.g. multiple hospitals), modes (e.g. pharmacy data to labs data), and over time.
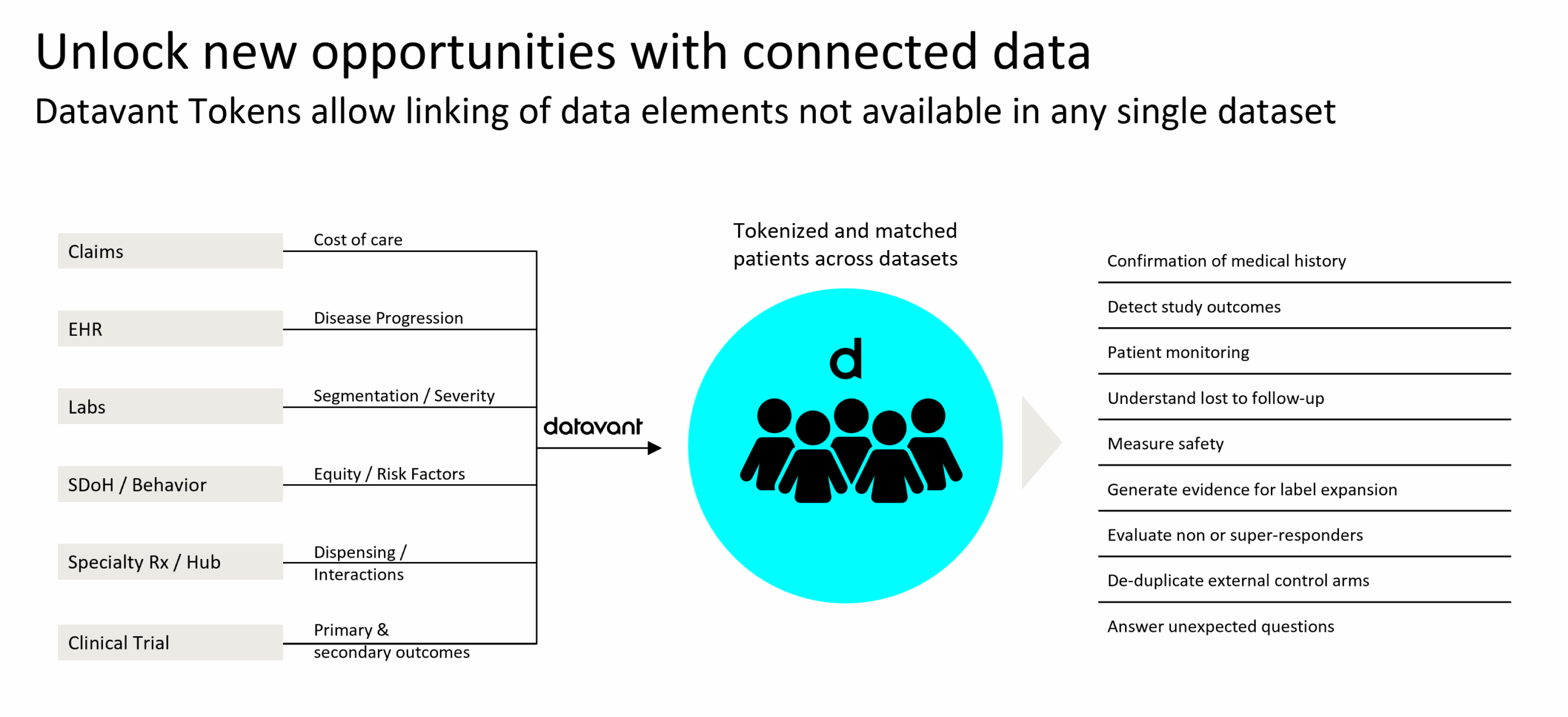
Datavant’s tokenization technology is a straightforward process that uses personally identifiable information (PII; e.g. first name, last name) on patients enrolled in a clinical trial or within an existing identified database to create a universal, de-identified key that can be referenced to link records across multiple datasets. This de-identified patient key is referred to as a “token.” Custodians and processors of health data use the token in many ways, but a few of them are fundamental. First, they use tokenization to enhance privacy and increase security (hashing, encrypting) as expected under various data privacy regulations. Second, given that layer of privacy protection, they use tokenization to achieve identity resolution across continually syncing data from one or more sources. Third, they use tokenization as a pre-processing step to compliantly share important non-personal information data as insights to inform data partnerships or health research analytics.
Our team continues to expand our work in Europe and with more and more stakeholders in the health system. We will continue to expand the map of the European data ecosystem.
Interested in learning more about the availability of global health data? Download the whitepaper, Fixing the Global Health Data Supply Chain.

