
Data Science for Product Development
At Datavant, our goal is to connect the world’s healthcare data by building tools to enable healthcare data to be shared in a way that is secure, compliant, and so that the data retains value. The data science team at Datavant is responsible for meaningful pieces of product development, and we have strived to build our org structure accordingly.
To give an example, one product the Data Science team works on is Match, our tool for reconciling patient IDs underlying disparate patient records. A critical component of the ID assignment process is the machine learning model that determines whether a pair of similar records — for example a pair of records with the same last name and date of birth but different zip codes — belong to the same individual. We have grappled with how to divide ownership between the development of the model and its deployment to production, and more broadly how to structure our Data Science team within our broader product development function.
What we’re solving for
We felt strongly about having a model development process that is tightly integrated with production systems in order to circumvent a slew of challenges that can otherwise arise. The most tangible hurdle is the alignment of the technical requirements of the model and the production environment, which limits velocity if not managed properly. A less visible but equally impactful risk is the potential that is left unrealized when production requirements are treated as black box constraints rather than frameworks with a degree of malleability tethered to certain nonnegotiable principles. Moreover, a lack of synergy between model development and deployment can also reverberate beyond the walls of engineering, as business and product stakeholders are liable to receive disparate timelines from different groups if there is not a single technical owner.
Although none of these issues are insurmountable with the right coordination and culture, at Datavant we have actively sought to mitigate them through our org structure. More precisely, we aimed to optimize development efficiency, visibility within and outside of engineering, and personal growth.
Our approach
To do this, we built a custom objective function from these three variables and modeled these variables as stochastic processes with initial conditions determined by various team alignments. Just kidding. To do this, we put our data science team within our broader engineering org; this means that data scientists go through the same technical onboarding as software engineers — setting up environments, access to resources, etc., which helps remove collaboration bottlenecks.
Going one step further, data scientists are part of our engineering product pod structure. Product pods are led by a product manager and consist of a mix of data scientists and software engineers, depending on the product needs (there are several pods without data scientists). Returning to the example of Datavant Match, this product is owned by Datavant’s “Identity” pod, which is responsible for solutions around patient identities. The pod contains a mix of data scientists and software engineers, but operates as a single group. For example, there is a single roadmap that incorporates both model development and deployment, and daily standups and weekly open-ended discussions include the full pod as a single team.
Trade offs from our approach
We have found several tangible advantages from this structural approach.
More efficient development
- Less overhead coordinating model development and deployment.
- Empowered and smarter decision making as a result of more context. For example, we want to avoid a data scientist feeling “we can’t do X because engineering won’t support it”.
- Testing: there is a shared understanding of which functionality should be tested within the scope of model development, and which should be part of production testing.
- There are no surprises when it comes to dependencies.
- We can design an optimal process for model productionization without having to compromise functionality for the sake of a simpler framework.
Joint sequencing, prioritization, and accountability
- We can sequence our work so that infrastructure necessary to support models is not a bottleneck. For example, we can build a Python microservice to support more sophisticated model functionality concurrently with the development of such functionality.
- There is a single owner of prioritization, leading to more efficient planning and clearer visibility.
- If certain areas of the roadmap are behind schedule, we can allocate resources from a broader pool since there is shared context between software engineers and data scientists.
Opportunity for growth
- Data scientists and software engineers are exposed to and have the opportunity to take on a broader range of technical work.
There will be tradeoffs to any organizational structure, and there are drawbacks with our model, including:
Agile development for data science
- Biweekly sprints with tightly scoped tickets is not the most natural framework to manage some of the exploration and experimentation required for model development, both for data scientists and stakeholders. We have sought to address this with clear designations and documentation around the type of work that each ticket entails.
Data science identity
- With our horizontal team structure, there is less natural interaction within the data science team. We have mitigated this with weekly, cross-pod check-ins for the data science team, in addition to biweekly meetings for team members to present on an aspect of what they’re working on, or recent developments in data science.
Redundant DS tooling
- Since data scientists are building tools in support of a particular product area, there is more possibility to build out capabilities with overlapping functionality rather than a single, cleaner data science toolbox built for multiple use cases.
These downsides would be more naturally mitigated if our Data Science team were structured as an atomic unit that played a consultative role to other functions in the organization rather than our horizontal model of team members embedded within these functions.
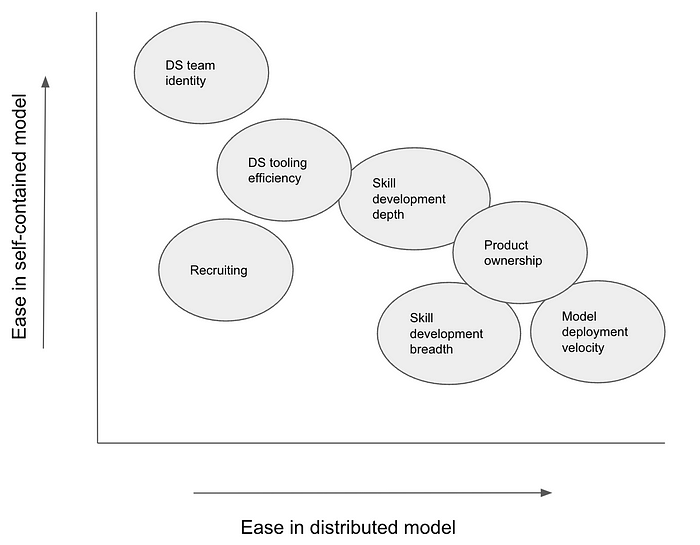
We can represent some of these tradeoffs graphically:
Broader context
The responsibility of data science teams can vary widely across companies, ranging from forecasting revenue, to building dashboards, to policy research, and we certainly wouldn’t expect our org structure to work in any situation.
The modularity of our product pods has also enabled this embedded model to succeed. Each engineering product pod has end-to-end ownership of the product, including implementation of company-level compliance and security measures (erring on the side of ownership is consistent with our broader cultural value of more responsibility, fewer rules). Some of the utility of our embedded model would be diminished if these constraints were managed entirely by a separate team.
As our engineering team scales from 70 to several hundred in the coming years, we will need to continue to evaluate our approach so the data science team can continue to meet the needs of the business.

